
Chapitre #01 - 2024
Qualité du Web
Bienvenue dans le premier chapitre numérique de la Revue Hypertexte®. Si vous êtes ici, c’est que vous croyez en ce projet et que vous avez soutenu la création d’un nouveau média dédié à ceux qui créent le Web et qui souhaitent mieux le comprendre. Nous parlons de surfer sur le Web, alors nous souhaitons que cette revue nous donne à tous les clefs pour naviguer avec sérénité, conscience des enjeux sociaux, environnementaux et politiques de notre contribution à cet univers virtuel.
Un chapitre numérique est publié chaque mois sous la forme d’un document à défiler. Plusieurs médias se complètent, vous avez la possibilité de consulter le chapitre de façon linéaire ou d’en grignoter des morceaux en fonction de vos envies. À la fin de l’année, une édition imprimée de tous les chapitres de l’année sera commercialisée.
Pour une expérience Grand Format optimale, nous vous conseillons de consulter ce chapitre depuis un grand écran (tablette ou ordinateur).

Édito : Pourquoi réfléchir et écrire sur la qualité du Web ?
Le premier chapitre de ce nouveau média mérite bien son éditorial. Il y a quelques années de cela, j’ai trouvé dans une boîte de don de livres un exemplaire de la collection « Que sais-je ? » intitulée Les vidéocommunications. Il a été publié en 1992, j’avais 3 ans et je jouais à écrire mon long prénom sur le clavier d’un Amstrad et je recopiais des lignes de scripts pour lancer des animations sur cet écran vert et vert clair. C’est la première interaction que j’ai eue avec un ordinateur.
Peut-on me considérer, moi la Millenial, en tant que digital native ? Pas vraiment je pense. Car j’ai appris Internet alors que les générations d’aujourd’hui vivent avec Internet. Cet espace virtuel nous entoure et fait partie intégrante de nos quotidiens. Il suffit de voir tout le temps passé sur un smartphone collé au creux de la paume. En France, l’Institut National de la Statistique et des Études Économiques indique qu’en 2021 il y avait 95 % de la population âgée de 15 ans ou plus qui dispose d’un smartphone. Évidemment nous pouvons nous dire que ce chiffre a augmenté et que cela ne compte pas toutes les tablettes et téléphones confiées à un enfant plus jeune pour une vidéo éducative ou tout simplement l’occuper. Internet, une évidence ? La réponse « oui » est sans aucun doute une illusion. Nous n’avons toujours pas compris les enjeux réels que cela implique dans nos vies. Les derniers débats autour de l’intelligence artificielle n’en sont qu’une illustration.
Les vérités d’Internet ne sont peut-être pas encore écrites dans des livres, dans des manuels comme ce « Que sais-je ? ». Commençons ici la nouvelle esquisse pour un portrait du Web.
Syphaïwong Bay.
Fondatrice de la Revue Hypertexte.
René Wallstein, Les vidéocommunications, collection « Que sais-je ? », 1992

Section 1
La qualité des contenus que nous servons et dont nous nous servons.
L’Internet permet des miracles. Grâce à ce réseau d’ordinateurs connectés ensemble, des millions d’utilisateurs créent et mettent en ligne des contenus. Ils veulent partager le contenu de leur dernier repas au restaurant ou participer à un débat. Chacun a sa vision de ce que devrait être le Web et de ce qu’est un contenu de qualité. Cette appréciation évolue également en fonction des avancées technologiques. L’Internet d’aujourd’hui n’est certainement pas le même que celui qu’avait projeté, à court-terme, Tim Berners-Lee lorsqu’il inventa le HTML, le concept d’URL et le protocole HTTP. C’était il y a seulement 43 ans.
Définir les standards de qualité quand les consommateurs évoluent.
« Il y a un côté un peu artificiel »
On va même au-delà de la réalité... c’est presque une image de synthèse comme dans un jeu vidéo. »
Notre invitée : Amélie Lachat
Directrice Digital, Marketing et Communication du groupe l’Orange bleue
Ex-Head of Research Neuron Partners
LinkedIn : https://www.linkedin.com/in/amelie-lachat/

« Deutsche Qualität » (Opel), « Artigiani della qualità » (devenu « Autentica qualità » dernièrement) pour Poltron e Sofa ou « Be a yardstick of quality. (Some people aren't used to an environment where excellence is expected.) » de Steve Jobs, sont des expressions, slogans ou citations facilement identifiables, connus de beaucoup. Avec comme point commun ce même mot qui démontre sans détours, l’importance du terme qualité.
Notre société moderne n’a de cesse de mettre en avant ce concept de qualité, en la mesurant sur une échelle plus ou moins complexe en fonction des situations. On en parle le plus souvent comme un concept descriptif qui permet à un produit ou un service d’être considéré de bonne ou mauvaise qualité, de qualité supérieure ou inférieure. C’est le sens que lui donne son origine étymologique : «la qualité correspond aux caractéristiques ou propriétés d’un concept ou d’un produit qui permettront de le spécifier ». Elle représente «une manière d’être non mesurable (d’une chose) qui donne une valeur plus ou moins grande (s’oppose à quantité) ». Par exemple, une chaise est de bonne qualité, car elle est fabriquée avec du chêne, une essence de bois solide et durable. Avec le temps, la qualité est devenue un concept aux facettes plus complexes, basée sur la capacité d’un produit ou service de satisfaire les besoins et attentes exprimés par un individu. Ainsi, la chaise évoquée précédemment, décrite comme de bonne qualité technique, pourra ne pas être en haut de l’échelle de qualité perçue en fonction du confort ressenti par son propriétaire. Nous prendrons le temps, dans la suite de cet article, de définir les différents concepts de qualité.
Au fil du temps, la qualité s’est imposée comme un critère de plus en plus important dans la prise de décision des individus, tant dans le monde professionnel que personnel. La question se pose alors : pourquoi opter pour un produit de meilleure qualité malgré un prix plus élevé et un temps de fabrication plus long, à l’instar d’un produit moins cher et disponible immédiatement, mais que l’on sait de moins bonne qualité ? Ces interrogations s’étendent bien au-delà du cadre des produits ou services. La considération de la qualité exerce une influence sur tous les aspects de la vie quotidienne. Des produits que nous consommons aux expériences que nous vivons, la qualité est devenue un critère qui guide nos choix et nos préférences.
Cette exigence croissante touche de nombreux secteurs, et n'est pas sans effet sur les producteurs de contenu. Dans le monde numérique en perpétuelle évolution, où l'information se propage à la vitesse de la lumière et où l'attention des consommateurs est une ressource précieuse, « le contenu de qualité” est devenu essentiel. Que ce soit dans les domaines de l'écrit, de l'audiovisuel, ou de l'interactif, les créateurs sont confrontés à une pression accrue pour produire des textes et images qui captivent, éduquent ou qui divertissent tout en offrant une expérience enrichie. Les plateformes de streaming telles que Netflix cherchent à répondre, elles aussi, aux attentes des consommateurs qui réclament une meilleure qualité de l’image (le forfait premium pour des contenus UHD/4K), une expérience visuelle utilisateur simplifiée (une interface pensée pour trouver facilement le contenu souhaité), du contenu visuel à valeur ajoutée (choix pendant le film, ajout d’informations supplémentaires). Les créateurs n’ont d’autre choix que d’investir davantage dans la production de contenus visuels de qualité supérieure pour rester compétitif et satisfaire l’usager.
Cet impératif constant vers des standards de qualité plus élevés souligne également l'importance de l'innovation et de la recherche. Les avancées technologiques et les nouvelles méthodes de production deviennent des alliés indispensables pour répondre aux attentes des consommateurs pour maintenir une qualité qui surpasse les demandes d'une société toujours plus exigeante.
Dans cet article, nous parlerons plus particulièrement de la qualité des contenus visuels et plus précisément de ceux pouvant être médiatisés par un écran, c'est-à-dire visible grâce à l’intermédiaire de l’écran. Le contenu a toujours existé, sur des murs pour représenter les images du quotidien, sur des toiles ou des feuilles pour représenter le vécu et l’imaginaire, pour un jour commencer à apparaître sur des écrans.
Aujourd'hui, le contenu visuel est omniprésent, déployant ses attraits dans chaque recoin de la vie moderne. Des télévisions qui trônent dans les salons, diffusant une variété infinie de programmes, aux smartphones devenus une extension de l’individu fournissant un accès instantané à un océan de contenu, l’image est devenue le fer de lance de la communication. Les écrans publicitaires, auparavant dominés par l’impression sur papier grand format, se tournent désormais vers un contenu numérique, voire interactif, capitalisant sur l'engagement et l'interactivité pour capter l'attention des consommateurs toujours plus connectés. Le consommateur cherche par exemple sur les réseaux sociaux, des photos esthétiquement agréables et des vidéos immersives grâce à une qualité technique proposée toujours plus grande, notamment grâce à l’innovation apportée au système de prise de vue des caméras par exemple. Il recherche aussi la fiabilité de la compression de l’image, la vitesse de transmission de l’information… à laquelle s’additionne une demande de contenus captivants pour une qualité perçue de l’expérience toujours supérieure.
Cette transformation reflète non seulement une évolution technologique, mais aussi une mutation dans la façon dont les individus perçoivent et consomment l'information visuelle. De simple support artistique à outil de communication et de commerce incontournable, le contenu visuel a traversé les années pour devenir le pilier central de la consommation et de l’interaction quotidienne.
La qualité se définit au sein d’un spectre
La course à la qualité sous-entend un souci constant d'amélioration, tant sur le plan technique que conceptuel. En effet, la notion de qualité dans son ensemble englobe un spectre complexe de concepts inter reliés, mais bien distincts.
Tout d'abord, la qualité technique représente l'aspect mesurable et objectif d'un produit ou d'un service. Elle se réfère aux spécifications, aux normes, et aux caractéristiques tangibles qui déterminent la performance, la fiabilité et la durabilité d'un produit. Par exemple, dans le domaine des écrans, la résolution, la fréquence de rafraîchissement, la fidélité des couleurs et la technologie d'affichage constituent des critères techniques évaluables. La qualité d’un produit ou d’un service va pouvoir se définir par sa manufacture, son apparence ou sa fonctionnalité. La qualité technique de la SD (Standard Definition) peut objectivement être comparée à la HD (Haute Définition) et à l’UHD (Ultra Haute Définition).

En parallèle, la qualité perçue émerge de la perspective personnelle et partiale de l'utilisateur. Elle se focalise sur l'expérience, les impressions et les émotions ressenties lors de l'utilisation ou de l'interaction avec un produit ou un service. Bien que difficile à quantifier, elle prend en compte des éléments tels que le design, l'ergonomie, la convivialité, la satisfaction globale ou la réponse du produit, face aux attentes de l'utilisateur. Dans le contexte des écrans, la qualité perçue pourrait être déterminée par l’impression de retranscription fidèle à la réalité, la facilité de navigation dans les menus ou grâce à une réactivité tactile optimale, influençant ainsi la perception de l'utilisateur sur la qualité de l'écran. Dans un contenu UHD, la couleur du ciel, le détail des feuilles des arbres est décrit comme de qualité perçue supérieure au même contenu en HD ou SD. Cela nous conduit alors vers la qualité perçue, qui façonne nos perceptions, nos jugements et nos interactions avec le monde qui nous entoure.
Enfin, la qualité se considère comme un critère subjectif, qui repose sur les préférences individuelles et les attentes personnelles. Elle varie en fonction des besoins spécifiques de chaque utilisateur et de son contexte d'utilisation. Ce critère prend en compte les facteurs contextuels, culturels, sociétaux et personnels qui vont façonner la perception individuelle de la qualité. Par exemple, pour certains utilisateurs, une qualité d'image optimale peut se traduire par des couleurs vibrantes, tandis que pour d'autres, cela peut signifier une fidélité des couleurs précises.
Ces trois concepts interagissent pour former une perception holistique de la qualité. La qualité technique établit les fondations objectives, la qualité perçue s’appuie sur l'expérience vécue, et la qualité en tant que critère subjectif s'ajuste aux préférences individuelles. Comprendre ces nuances permet de mieux évaluer, concevoir et offrir des produits et des services qui répondent aux attentes des utilisateurs tout en cherchant à atteindre un équilibre entre objectivité et subjectivité dans la définition de la qualité.
Les écrans influencent la perception de la qualité des contenus.
Le contenu qui nous intéresse dans ce travail est celui qui est médiatisé par un écran. Pour rappel, cela s’exprime par la présence d’un intermédiaire entre le contenu visuel et l’individu, nommé vecteur ou médium dans certains champs académiques. Par définition, un écran est une surface ou une interface qui affiche des informations visuelles, telles que des images, des textes ou des données, généralement grâce à une technologie d'affichage électronique.
Il peut prendre différentes formes, comme les écrans d'ordinateurs, de téléphones portables, de télévisions ou de tablettes et utilise diverses technologies telles que « LCD” (affichage à cristaux liquides), « LED” (diodes électroluminescentes) ou « OLED” (diodes électroluminescentes organiques) pour afficher des contenus visuels. L'écran est l’interface entre l'utilisateur et les informations, permettant la visualisation, voire l'interaction avec le contenu affiché.
Cet objet technologique qu’est l’écran, à l'évolution rapide, reflète notre quête incessante pour améliorer et transformer notre expérience visuelle. Des premiers écrans cathodiques monochromes aux écrans ultra haute définition incurvés que nous connaissons aujourd'hui dans nos smart TV, chaque étape a représenté un bond en avant technologique significatif. Parallèlement, la taille des écrans a connu une croissance exponentielle, passant de dimensions modestes à des écrans géants utilisés dans diverses applications, de l'informatique à la télévision, en passant par la signalisation numérique ou l’évènementiel.
L'écran s'est imposé comme un compagnon omniprésent dans le tissu de nos vies modernes. Qu'il soit niché au creux de nos paumes sous la forme d'un smartphone, sur nos bureaux en tant qu'ordinateur fidèle, ou qu'il occupe la moitié de nos salons, l'écran a remodelé notre relation avec l'information et le divertissement. L'ère numérique contemporaine a transformé notre interaction avec le monde extérieur, reléguant les supports imprimés au second plan. Si l’on se pose un instant et que l’on réfléchit à notre quotidien, il existe peu d'endroits où l’écran n’est pas présent (en ayant au passage souvent remplacé le papier). Nos agendas, les horaires de train en gare, la projection d’un cours en classe, la commande de denrées alimentaires… Aux États Unis, les adultes passent environ 7 h par jour devant un écran (source Nielsen). En France, on estime ce chiffre à environ 5 h (source Médiamétrie).
Cependant, derrière sa surface lumineuse se cachent des mécanismes complexes, une combinaison sophistiquée de pixels, de rétroéclairage et de circuits électroniques, travaillant de concert pour traduire et transmettre des images, des textes et des données. L'écran va au-delà de sa simple fonction d'affichage, car l’ensemble des informations transmises ont un impact physiologique ou psychologique. L'œil, avec ses capteurs sensoriels, va transmettre une information au cerveau, qui pourra entraîner une réaction émotionnelle, le rappel d’un souvenir, etc. C'est une passerelle entre le réel et le virtuel, dans laquelle la qualité du contenu joue un rôle important.
Limites de cette « qualité perçue ».
Toutefois, nous devons être conscients d'un éventuel seuil dans la perception visuelle. L'œil humain, un organe sensoriel doté de cellules aux propriétés variées, est naturellement limité par le spectre visible. En revanche, l'écran, objet technologique, se forme de composants programmables et uniformes, apparemment sans limites. Il en découle une réflexion sur la pertinence de ce qui sera observé : l'amélioration des caractéristiques techniques de l'image ne reproduit pas nécessairement les capacités de l'œil humain de manière fidèle, et cette différence pourrait influencer de manière significative la qualité perçue. En d'autres termes, grâce à ses améliorations techniques continues, l'écran pourrait finir par produire une précision dans l'image médiatisée qui excède les capacités de perception de l'œil humain.
Dans le cadre de ma thèse sur la perception de l'Ultra Haute Définition (UHD), il était essentiel de comprendre les paramètres techniques qui définissent une image sur un écran : la définition, la couleur, la fréquence et la luminance. Ces éléments constituent la base de la recherche et développement dans le secteur des écrans, visant à améliorer l'expérience visuelle immersive des utilisateurs. En effet, dans des domaines aussi variés que le divertissement, la médecine ou la publicité, une qualité d'image optimisée joue un rôle crucial.
Pour saisir pleinement l'impact de l'amélioration technique sur la qualité perçue, trois études qualitatives ont été menées dans des contextes similaires à un salon domestique. Nos participants ont expérimenté des contenus UHD variés, dans des conditions optimales établies par des normes internationales. Les résultats de ces études révèlent une perception notable de l'amélioration de la qualité technique de l’image…
Notre système visuel est donc encore réceptif aux améliorations de ces critères techniques. Cependant, nous avons mené des études quantitatives complémentaires qui ont montré que l’amélioration de la qualité perçue entre l’UHD et la HD, était plus faible qu’entre la HD et la SD. Allons-nous atteindre un seuil de la qualité que nous pouvons percevoir prochainement ?

Malgré cette limite potentielle sur les différences perçues entre ces qualités techniques, un autre phénomène a été relevé, celui de l’immersion. Les participants ont ressenti les images comme étant plus réalistes, parfois même au point de ne plus percevoir l'écran comme un intermédiaire, mais plutôt comme une fenêtre sur la réalité.
Ces constatations soulignent comment l'évolution technique, en particulier l'UHD, influence la perception de réalisme et l'immersion dans les images, rapprochant ainsi l'expérience visuelle de la scène réelle. Elles invitent par ailleurs à réfléchir sur la corrélation entre l'amélioration technique et la qualité perçue, ainsi que sur l'impact de ces avancées sur notre expérience quotidienne des médias.
L’hyperréalité est-elle hors de la réalité ?
Ces résultats ont également confirmé les aspirations des professionnels de l'audiovisuel en quête d'une expérience visuelle à proposer, proche de la réalité. Leur objectif est logiquement de présenter des contenus où les détails sont visibles avec des couleurs fidèles, une impression de vitesse réaliste, un ensemble d’éléments permettant l’immersion et ainsi créer une expérience virtuelle qui reflète fidèlement la scène originale. Des expériences complémentaires, non mentionnées ici, ont également révélé que cette fidélité est rendue possible par l'amélioration des paramètres techniques de l'image, tels que la netteté, les contrastes, la luminosité et la gamme de couleurs.
Néanmoins, certains participants décrivent l'expérience visuelle vécue avec l'UHD comme allant au-delà d'une simple perception de la réalité. Ils évoquent un sentiment de réalisme surpassant la réalité elle-même, une sorte de perception « hors de la réalité». Ils rapportent davantage de détails que ce qu'ils auraient pu percevoir dans la scène originale. Cette sensation, décrite dans divers contextes comme le sport, la nature ou les concerts, amène à une confusion potentielle entre l'UHD et des technologies telles que la réalité augmentée ou virtuelle. Cependant, contrairement à ces dernières, qui créent ou complètent une réalité synthétisée, l'UHD vise simplement à reproduire la réalité avec une plus grande fidélité
La qualité perçue offerte par l'UHD atteint ainsi une dimension hyper-réelle, décrite dans la littérature comme l'hyperréalité, un concept abordé par des penseurs comme Jean Baudrillard et Umberto Eco. Elle est décrite comme une représentation tellement fidèle et intense de la réalité que la distinction entre ce qui est réel et ce qui est simulé via un médium, devient flou. Cette hyperréalité, rendue possible par les avancées de l'UHD, interroge notre perception de la réalité et la frontière entre le monde réel et la représentation technologiquement avancée de ce monde.
Il apparaît alors nécessaire de questionner si la poursuite d'une fidélité à la réalité dépassée est véritablement souhaitable. En effet, certains utilisateurs ont exprimé un sentiment d'artificialité face à ces images hyperréalistes, voire une impression d'irréalité : « Il y a un côté un peu artificiel », « On va même au-delà de la réalité... c'est presque une image de synthèse comme dans un jeu vidéo ». Cette amélioration de la qualité perçue, bien que perceptible et mesurable, est parfois perçue comme excessive ou même négative, selon le type de contenu affiché.
Il est clair que l'augmentation de la qualité technique de l'image, de la HD à l'UHD, influence positivement la fidélité perçue à la réalité et le sentiment d'immersion. Cependant, la relation entre la qualité perçue et la fidélité à la réalité semble non linéaire. À un certain niveau, les images hyperréalistes peuvent donner une impression de dépassement de la réalité, devenant artificielles et perturbant l'immersion. Ces constatations mettent en lumière la complexité de l'expérience visuelle dans l'ère de l'UHD, variant selon le contenu des images.

En résumé, nos études mettent en lumière une réalité complexe : malgré l'amélioration technique qui accroît la qualité perçue des images, les résultats ne correspondent pas toujours aux attentes individuelles. Cette dichotomie entre la perfection technique et la résonance émotionnelle personnelle met en évidence l'importance cruciale de comprendre les nuances de la perception humaine. L'hyperréalité, où la frontière entre le réel et le virtuel devient floue, offre une expérience immersive qui défie notre compréhension traditionnelle de la réalité. Elle soulève des questions fondamentales sur la manière dont l'évolution technique doit être harmonisée avec les réactions émotionnelles et sensorielles des individus
Ainsi, la production de contenu de qualité ne se limite pas à la poursuite de la perfection technique. Elle implique une compréhension empathique des besoins, des attentes et de la psychologie du public. Les créateurs de contenu doivent alors jongler entre l'innovation technologique et une approche centrée sur l'utilisateur, cherchant à créer des expériences qui non seulement impressionnent par leur qualité, mais qui résonnent également sur le plan émotionnel et psychologique. Ce défi souligne l'importance d'une approche multidisciplinaire dans la création de contenu, où la technologie, l'art, la psychologie et la sociologie convergent pour enrichir l'expérience humaine. Dans cette quête, il est essentiel de reconnaître que la technologie est un outil pour améliorer la communication humaine et non une fin en soi. En définitive, l'objectif ultime est d'atteindre un équilibre délicat où le contenu de qualité ne se définit pas uniquement par ses aspects techniques, mais aussi par sa capacité à engager, à émouvoir et à connecter les gens dans un monde de plus en plus numérisé.
Section 2
La domination des moteurs de recherche et notre sentiment de qualité.

Philip K. Dick est l’auteur du roman de science-fiction Les androïdes rêvent-ils de moutons électriques ? publié en 1968. C’est le thème repris dans le très célèbre film Blade Runner de Ridley Scott dans lequel Harrison Ford interprète le personnage enquêteur de Rick Deckard partagé entre les dangers des androïds déviants et ses propres sentiments pour un de ces androïds. Les robots et les algorithmiques, eux, rêvent-ils de qualité ?
Notre invité : Sylvain Peyronnet
Créateur d’algorithmes pour YourText.Guru et Babbar.Tech.
LinkedIn : https://www.linkedin.com/in/sypsyp

Les algorithmiques rêvent-ils de contenus de qualité ?
Qu’est-ce que la qualité ? cette simple question est en réalité très complexe, elle a agité - et agite encore – les philosophes.
Si on remonte le temps jusqu’à Descartes, on découvre une distinction entre les qualités premières et les qualités secondaires. Les qualités premières d’un objet en sont les éléments objectifs et mesurables, tandis que ses qualités secondaires dépendent de la perception que l’on a de cet objet. Je reviendrais sur ce point par ricochet un peu plus loin dans cet article car cette connexion entre la qualité et la perception se retrouve dans l’aspect contextuel de la qualité perçue par les humains.
L’acception plus moderne du terme qualité est de dire que c’est le fait qu’un « objet » (qui peut être animé ou inanimé, une chose ou une personne par exemple) est bon ou mauvais, dans le sens d’inférieur ou supérieur à la moyenne. Et on verra que cette définition finalement assez populaire est en fait la « bonne » définition pour travailler sur le Web.
Si vous lisez cet article vous êtes peut-être un professionnel du Web. Le Web, on y accède souvent par un moteur de recherche, qui va tenter d’algorithmiser la notion de qualité, pour répondre de manière fiable aux besoins informationnels exprimés par ses utilisateurs. Aujourd’hui mon propos est de donner quelques pistes de réflexion sur ce qu’est cette notion de qualité algorithmique pour le Web, dans le cas particulier de contenus qui sont largement composés de texte (très concrètement : des pages de sites Web). Le discours sera par ailleurs centré sur l’évaluation des contenus par un moteur de recherche, principal opérateur algorithmique sur le Web.
Après avoir discuté de la définition même de la qualité, nous verrons ensuite deux approches différentes : l’une voit la qualité comme un absolu que le moteur va vouloir quantifier et prédire, et une deuxième va être plus dynamique, mesurant ainsi la qualité perçue par des humains en contexte.

Qui était René Descartes ?
René Descartes (1596-1650) était un mathématicien, physicien et philosophe français. Il est reconnu comme l'un des pionniers de la philosophie moderne, surtout célèbre pour son principe du cogito, « Je pense, donc je suis », établi dans son œuvre Discours de la méthode. Ce principe fonde les sciences sur la base du sujet connaissant et sa perception du monde. En physique, Descartes a contribué à l'optique et est vu comme un des fondateurs du mécanisme. En mathématiques, il a créé la géométrie analytique. Certaines de ses théories, comme celle de l’animal-machine et des tourbillons, ont été par la suite contestées ou abandonnées. Le cogito est considéré comme le point de départ de la subjectivité moderne.
Image : After Frans Hals, Public domain, via Wikimedia Commons
NDLR
Qu’est-ce que la qualité dans le contexte des pages Web ?
La qualité est dans l’œil de l’évaluateur
C’est la première chose qu’il faut retenir : la notion de qualité est en pratique une notion contextuelle. C’est l’état d’esprit dans lequel on est à un moment donné qui va faire que l’on attribue à un objet une grande valeur d’utilité ou au contraire qu’on va lui associer une pénibilité à devoir le gérer.
Au niveau du Web, cet aspect est fondamental. Lorsque l’on fait des opérations de quality rating, c’est à dire des études où l’on va missionner des humains pour dire si des contenus sont de bonne ou mauvaise qualité, voire même s'ils portent une intention trompeuse (on parle alors de spam), on se rend compte que certaines pages Web font consensus (voir la figure 1 par exemple), tandis que d’autres vont avoir une perception qui dépend du contexte. L’exemple de la figure 2 est à ce titre édifiant : une page d’un site e-commerce sera considérée de qualité lorsque le visiteur sera lui-même “en” intention d’achat, alors que le reste du temps il va la considérer comme de mauvaise qualité. C’est en réalité assez intriguant, car l’information portée par la page, et notamment sa validité en termes de description de la réalité, reste la même. C’est donc bien la psychologie de la personne qui lit le contenu qui changera la perception.
Charles Baudelaire (1821-1867) est connu pour sa poésie mais aussi pour sa qualité de critique d’art. En 1824, il présente l’appréciation de la poésie et de la qualité de la peinture comme étant le fruit du ressenti du spectateur.
NDLR

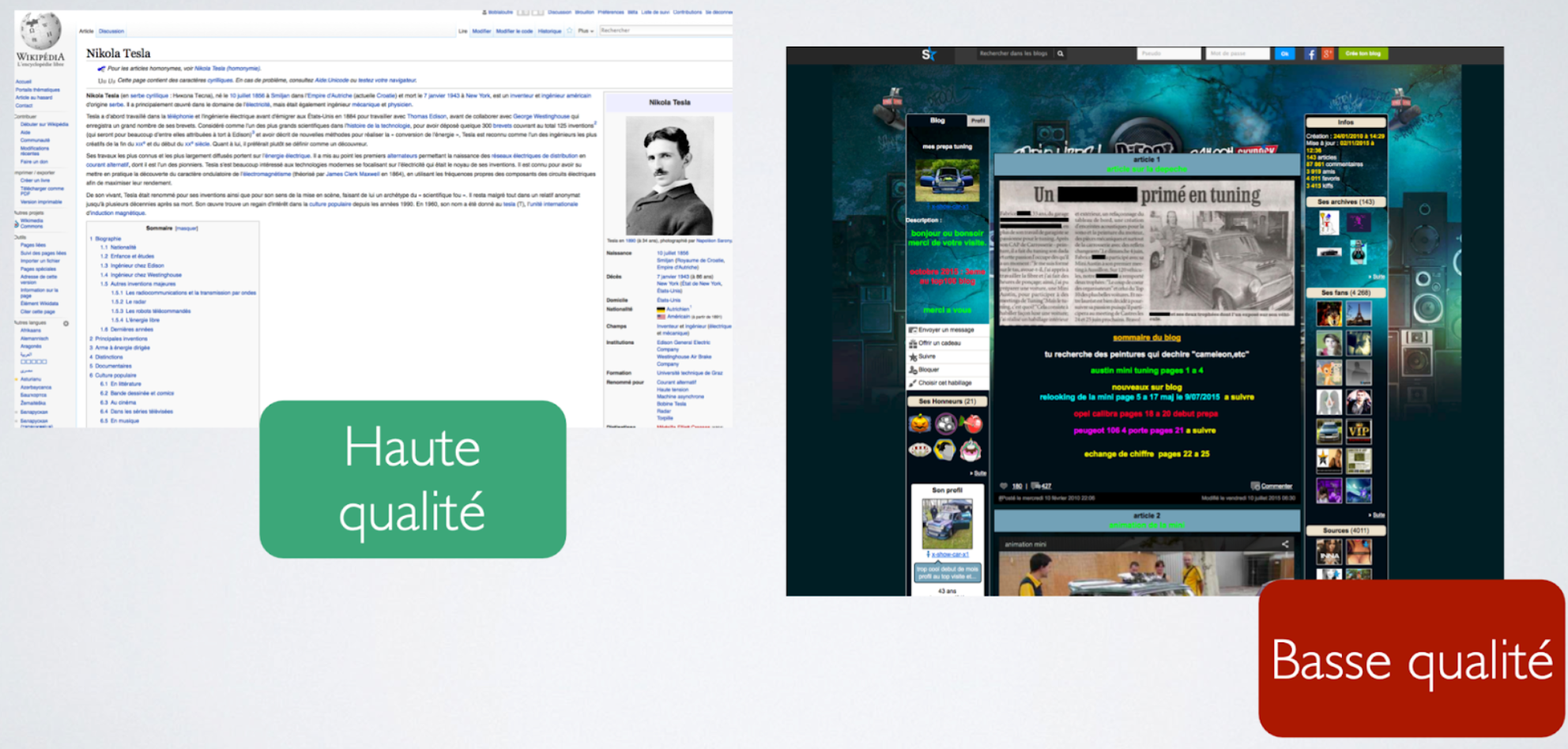

Pour les moteurs de recherches, l’enjeu va être de prédire pour chaque page du Web, si elle est de qualité suffisante pour pouvoir être mise en avant dans les résultats de recherche.
Un moteur fonctionne par classement, il va donc devoir choisir les pages les plus à même de satisfaire ses utilisateurs, dans un contexte qui n’est défini que par la requête qui est exprimée, et parfois par des informations implicites concernant l’utilisateur (par exemple un historique de navigation ou encore des informations de profilage publicitaire).
La qualité, une caractéristique absolue des pages Web
Avant les algorithmes, ce que le moteur veut mesurer
Par essence, le moteur de recherche veut proposer à ces utilisateurs des résultats qui le satisfont suffisamment pour qu’il ne choisisse pas d’utiliser un autre canal de recherche dans le futur. Pour cela, il va utiliser un dispositif algorithmique lourd, mais concernant les contenus, toute la machinerie vise à comprendre principalement deux aspects :
La pertinence de la réponse apportée au besoin informationnel. Quand on tape une requête, on a littéralement une idée en tête, et la première vertu d’une page Web doit être de répondre correctement à cette idée.
La qualité globale du contenu. Attention, car ici le mot qualité est vraiment là pour désigner la quantité de plaisir que l’on va trouver à lire/regarder le contenu.
C’est dans la mesure de la pertinence par un moteur que se situe l’aspect contextuel de la notion de qualité sur le Web. En effet, en analysant finement la requête (avec des algorithmes basés maintenant sur les modèles de langues, comme BERT par exemple), le moteur va comprendre assez précisément la question que l’humain se pose réellement (sans peut-être réussir à l’exprimer réellement).
Avec cette compréhension il pourra alors filtrer des pages, qui répondent bien à la question, parmi des milliers voire millions de pages Web qui portent sur le sujet général sous-jacent au besoin informationnel.
Concernant la qualité des contenus, c’est là que se situe la difficulté : comment déterminer qu’un contenu est susceptible de plaire ? Il y a plusieurs approches pour cela, et les moteurs utilisent toutes les approches. Elles sont cependant toutes basées sur des techniques issues de l’apprentissage automatique (machine learning en anglais).
Analyser le contenu a priori pour faire de la qualité un signal de classement
Une approche très simple à comprendre est celle qui consiste à faire de la qualité un signal de classement, c’est-à-dire l’un des nombreux signaux techniques que le moteur intègre pour fabriquer son classement.
La première équipe à avoir formalisé cette approche - dans le cadre de la détection du spam - est celle de Ntoulas et al.(1) L’approche consiste à calculer des signaux techniques nombreux et à utiliser un algorithme de classification (dans leur cas le C4.5 de Ross Quinlan) pour prédire le niveau de qualité qu’un humain associera à une page Web, à partir des métriques calculées sur cette page.
En 2014, nous avons reproduit(2) cette approche pour prédire (avec un niveau de précision d’environ 80%) si des contenus Web étaient de faible ou haute qualité, ou bien du spam. parmi les métriques techniques on trouve des choses comme le taux de compression du texte de la page, le nombre d’images, la longueur moyenne des mots, et bien d’autres critères encore (plusieurs dizaines).

Figure 3. Qualité versus un signal (densité du terme le plus fréquent)
EN : Proportion du Bucket : Bucket Proportion
EN : Proportion du dataset : Dataset Proportion
EN : Qualité : Quality
EN : Spam : Spam Quality
EN : Haute : High Quality
EN : Densité du terme le plus fréquent : Density of most frequent term
La figure 3 illustre un phénomène qui nous avait marqué à l’époque. On y voit l’histogramme (en bas) des valeurs que prend un signal technique sur l’ensemble des pages du dataset évalué par des humains. Et on voit, en haut, les évaluations qui sont faites. Les deux courbes sont alignées, et on voit une chose frappante : le pic de perception de qualité coïncide avec le pic de normalité du dataset. La conclusion littérale est très simple : ce que les humains apprécient le plus, c’est ce qu’ils ont le plus l'habitude de voir.
Il faut vraiment comprendre que l’implication de ce phénomène est très spécifique : pour faire des contenus qui plaisent sur le Web, il faut écrire d’une manière que votre public a l’habitude de voir, ce n’est pas en cassant les codes que l’on maximise la perception positive de ses contenus !
Avec une multitude de signaux et un dataset suffisant, on peut mettre en place un processus de prédiction qui sera une suite de règles. Une suite de règles c’est par exemple : “si un texte à un taux de compression entre telle et telle valeur, des mots de taille moyenne 6 caractères, que le mot principal apparaît moins de 6 fois et qu’il y a plus de 12 images, alors le public trouvera le contenu de qualité”.
Bien entendu, s’agissant d’une approche basée sur de l’apprentissage automatique, il y aura des erreurs, des faux positifs et des faux négatifs, qui feront que le moteur n’aura pas toujours des résultats qui plaisent.
L’approche que je viens de vous décrire est au cœur de plusieurs algorithmes de Google ayant pour but de fournir des résultats de qualité. Le plus connu de ces algorithmes est probablement le filtre Panda(3), mis en place en 2011 et qui à permis à Google de rationaliser la notion de qualité en proposant des bonnes pratiques aux Webmasters.
Prédire mécaniquement la qualité n’est cependant pas une approche totalement satisfaisante, la versatilité des comportements humains induisant des fortes variations dans la perception de cette dernière.
La qualité perçue, pour un moteur qui s’adapte à son public
S’adapter à la réalité humaine pour corriger sa perception de la qualité
Pour mieux coller à la réalité, les moteurs ont adopté des approches plus dynamiques, basées sur le fait que mesurer la satisfaction de l’utilisateur en temps réel peut être vue comme une mesure de qualité. Le moteur estimera donc qu’est de qualité ce qui plaît au moment de la mesure et se réactualisera selon ce qu’il aura estimé.
L’avantage des moteurs de recherche, c’est qu’ils “surveillent” des cohortes d'utilisateurs qui ont tous des comportements finalement assez similaires. Grâce à cela, ils peuvent rapidement comprendre ce qui plaît, et ce qui ne plait pas.
Tous les algorithmes visant à modifier le comportement du moteur pour augmenter le niveau de qualité perçue par les utilisateurs se nourrissent du même type d’information : des préférences humaines, qui peuvent être atomiques (“j’aime/j’aime pas telle page”), par comparaison (“je préfère la page A à la page B”), ou encore par classement (“voici la liste ordonnée des pages que j’aime”). Les meilleures approches sont basées sur la mesure par comparaison, car avec ce type d’évaluation que l’humain révèle le mieux ses réelles préférences.
Pour capter ces préférences, le moteur peut les demander explicitement. Mais en pratique il procède autrement, en évaluant les préférences implicites. C’est en observant le comportement de l’utilisateur lorsqu’il interagit avec les résultats du classement que le moteur va comprendre les préférences.
Intuitivement on comprend bien que si un visiteur du moteur ne clique pas sur le lien vers une page Web c’est qu’il sait déjà, ou qu’il soupçonne fortement, que la page ne répondra pas à son besoin, ce qui implique qu’elle ne sera pas de qualité suffisante pour lui.
En pratique c’est un peu plus compliqué car il y a plusieurs temps forts dans le comportement du visiteur :
Présentation. C’est l’intervalle de temps entre le moment où le visiteur écrit sa requête et le moment où il va suivre un des liens.
Action. L'utilisateur a plusieurs actions possibles, mais la principale est le click sur l'un des résultats.
Visualisation. L'utilisateur a cliqué sur un lien, il visite la page cible de ce lien.
Les moteurs ont une vision complète de ce qui se passe lors des étapes 1 et 2. Pour l’étape 3 cela demande de la data tierce (par exemple issue d’un navigateur Web).
Ce que mesure le moteur de recherche en pratique
Il existe une littérature scientifique abondante sur ce sujet de la mesure de la préférence implicite. Mais l’article clé qui donne les principales approches, est celui de Radlinski et al(4).
Dans cet article, on découvre plusieurs patterns comportementaux qui indiquent les préférences des utilisateurs du moteur. La figure 4 directement tirée de l’article illustre les principaux motifs.

Figure 4. Patterns comportementaux au niveau de la page de résultats (tirée de Radlinski et al.).
Ces motifs s’inscrivent soit dans le suivi des actions sur une chaîne de requêtes (plusieurs requêtes successives de la part d’un même utilisateur), soit sur une seule requête. Ici je ne vais aborder que le cas d’un comportement mono-requête et je vous renvoie à l’article scientifique pour en savoir plus si vous le désirez.
Les deux schémas du haut de la figure 4 concernent les comportements mono-requête. A gauche on voit la notion de click-skip : pour une requête q, l’internaute va cliquer sur le troisième résultat (le X dans la figure), mais pas sur le premier et le deuxième. Indiquant de manière implicite qu’il pense que les deux premiers résultats sont moins pertinents que le troisième. Il crée ainsi deux paires de préférences qui pourront être utilisé ensuite par le moteur.
A droite on voit ce que l’on appelle un no-click second : l’utilisateur du moteur clique sur le premier résultat et ne revient jamais. C’est une confirmation implicite de la qualité du premier résultat.
Vous pouvez voir que ces motifs sont particulièrement simples, on peut donc se demander si ils encapsulent réellement les préférences.
C’est encore le même article qui nous permet de répondre. Le click-skip est par exemple correct à environ 80% (plus ou moins 5%), tandis que le no-click second n’est précis qu’à 63% (plus ou moins 16% !). D’autres motifs plus complexes permettent de gratter un peu encore sur la précision, en montant jusqu’à 84%. En combinant plusieurs motifs, Radlinski et al. nous explique que la meilleure précision obtenue est de 87%. C’est un score impressionnant, mais on voit qu’il y a encore un angle mort au niveau du moteur puisqu’une partie du temps il ne sera pas capable de réellement comprendre les préférences. Cela explique pourquoi les moteurs de recherche n’ont pas toujours les meilleurs résultats possibles.
Un autre point qui dégrade la prise de décision du moteur sur la qualité des résultats est la nécessité d’avoir le volume suffisant pour la significance statistique de la mesure. En effet, ce n’est pas parce que 3 personnes expriment une préférence qu’elle est correcte pour toute la population intéressée par un sujet. Il faut donc observer plusieurs milliers de personnes sur un même type de demande pour comprendre réellement les préférences. C’est pour cela que les résultats sont souvent meilleurs sur les mots clés à fort volume de recherche.
Mesurer les préférences implicites, mais pour en faire quoi ?
Il existe plusieurs pistes algorithmiques pour utiliser ces préférences implicites.
On peut s’en servir pour faire ce que l’on appelle du re-ranking, c'est-à-dire modifier un classement en inversant quelques résultats. Un article écrit par des chercheurs de Microsoft menés par Susan Dumais(5) explique ainsi que l’usage des motifs comportementaux pour faire du re-ranking améliore la qualité perçue drastiquement (près de 15% d’augmentation des métriques de satisfaction explicite).
Mais l'algorithme qui va être totalement centré autour de ces préférences est l'algorithme de learning-to-rank. Le principe du learning-to-rank est un principe d’apprentissage automatique par renforcement dont les premières approches ont été mises au point chez Altavista dans les années 90. Le propos de cet article n’est pas d’expliquer le learning-to-rank, je me contenterais donc de dire que l'algorithme va monitorer ses propres résultats via des préférences implicites mesurées par le moteur, pour se recalibrer de lui-même et ainsi améliorer ses résultats.
Même si l’approche date des années 90, c’est surtout les travaux de l’équipe de Chris Burges(6), chez Microsoft Bing, qui vont populariser cette approche. En effet, ces méthodes vont rapidement montrer une réussite exceptionnelle pour calculer vite un bien meilleur classement, en se basant principalement sur des préférences exprimées par les utilisateurs du moteur. Les algorithmes de learning-to-rank ont bien évolué depuis (Google en a même présenté un à base de réseaux de neurones profonds) mais tous se "nourrissent" des préférences implicites.
Le principe du learning-to-rank est un principe d’apprentissage automatique par renforcement dont les premières approches ont été mises au point chez Altavista dans les années 90.
Comme souvent pour des sujets un peu techniques il n’y a pas de réelle conclusion. Je vais donc surtout vous dire en quelques mots ce qu’il faut retenir de tout cela.
La notion de qualité est très humaine : elle est contextuelle et dynamique, ce qui la rend un peu insaisissable. D’un point de vue mécanique, les moteurs de recherche vont donc déployer des algorithmes de machine learning, les plus à même de mimer les décisions humaines, pour comprendre cette notion de qualité.
Plusieurs approches existent, certaines sont statiques et visent à noter de manière absolue des contenus, tandis que d’autres sont dynamiques et s’inscrivent dans une interaction avec les humains. Ces deux approches ne s’excluent pas, au contraire, les deux couches d’analyse existent, et l’une agit par-dessus l’autre
___
(1) Alexandros Ntoulas, Marc Najork, Mark Manasse, and Dennis Fetterly. Detecting Spam Web Pages Through Content Analysis. 15th International World Wide Web Conference (May 2006), pages 83-92.
(3) https://fr.wikipedia.org/wiki/Panda_(Google)
(4) Radlinski, Filip, and Thorsten Joachims. "Query chains: learning to rank from implicit feedback." Proceedings of the eleventh ACM SIGKDD international conference on Knowledge discovery in data mining. 2005.
(5) Agichtein, Eugene, Eric Brill, and Susan Dumais. ”Improving web search ranking by incorporating user behavior information.” Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2006.
(6) Burges, C., Shaked, T., Renshaw, E., Lazier, A., Deeds, M., Hamilton, N., & Hullender, G. (2005, August). Learning to rank using gradient descent. In Proceedings of the 22nd international conference on Machine learning (pp. 89-96).
Section 3
La qualité du Web dans la solidité de ses fondations.
Ce chapitre s’est concentré sur les notions de qualité de contenu d’un point de vue psychologique, émotionnelle mais aussi pour les moteurs de recherche. N’oublions pas que pour un Web de qualité et accessible, nous devons nous assurer de disposer d’infrastructures techniques solides.
Notre invité : Karim Slamani
IT Security Expert
LinkedIn : https://www.linkedin.com/in/karim-slamani-82a84825/

Ecoutez Karim Slamani nous expliquer le Plan de Reprise d’Activité et la gestion des risques informatiques. Il évoque avec nous tout particulièrement les protocoles en cas d’incident.
Podcast en français.
Les points clefs transcrits pour vous :
-
Le risque qui pèse sur un système d'information au sens large, ou sur un système informatique au sens large, il est assez général et il peut intervenir à plein de niveaux différents. Donc globalement tout le monde surestime sa capacité à protéger ou à intervenir sur le système d'information, mais tous les périmètres ne sont pas couverts et c'est de là que la faiblesse générale naît. La partie la plus difficile c'est justement d'essayer de mettre tout ça à plat, de donner le même niveau d'information à tout le monde et de faire en sorte qu'il n'y ait pas de trous dans la raquette.
Ce qui va être difficile c'est de faire parler les différents acteurs entre eux, de vérifier que les données d'entrée de l'un soient bien les données de sortie de l'autre.
Le système d'information est couvert par rapport à des cas qu'on aura probablement identifié sous chacun des angles de code, une erreur dans un code. Donc côté infra il n'y a pas de problème, côté code il semble ne pas y avoir de problème, côté sécurité il n'y en a pas, la question c'est l'utilisateur final à la fin. L’utilisateur final va se rendre compte qu'il y a un problème, il va savoir remonter aux équipes en général et la difficulté c'est de mettre le doigt sur le point problématique. Il faut que le gestionnaire de l’infrastructure puisse isoler rapidement le problème pour identifier le périmètre d’action afin que la personne en charge de la sécurité puisse faire exactement la même chose. Ensuite l’information arrive entre les mains du développeur. Ce dernier assume la recherche du problème pour le corriger.
-
La personne doit être assuré c'est vraiment le dérouler des différentes étapes. On va couper le site pour isoler les potentielles traces du pirate. On va couper le site pour mitiger l'attaque, c'est à dire si encore une exfiltration de données en cours, on la bloque et on essaye de figer l'existent pour chercher à déterminer la source potentielle de la vulnérabilité.
Ça peut être aussi de tout couper pour essayer de se donner une étendue des dégâts en cours ou des dégâts en terme d'exfiltration de données, qu'est-ce qui a été vu, qu'est-ce qui n'a pas été vu, quand on parle de données sensibles. Si c'est une vulnérabilité physique et une vulnérabilité côté code... comment faire pour la patcher. Est-ce que c'est rapide, est-ce qu'il faut mobiliser toutes les équipes de l'air, est-ce qu'il existe des patchs assez rapides à déployer pour se prémunir rapidement de l'attaque, est-ce qu'on a des sauvegardes à remettre en place s'il y a eu une destruction des données par exemple?
Si oui, est-ce qu'on est prêt à perdre une journée complète de données, est-ce qu'il ne faut pas isoler toutes les données qu'on pourrait perdre avant de remonter une sauvegarde. Une personne en panique a besoin d'un fil rouge conducteur, mais également d'avoir toutes ces options à disposition pour mitiger la répercussion de l'incident sur son business.
Ça peut être en termes d'image, ça peut être en termes de coupure du business. Le site peut être coupé pendant quelques minutes, heures, jours, le temps d'isoler la désinformation. Et voilà, c'est vraiment la notion de temps, et chaîne de commandement aussi qui va se mettre facilement en place dans le sens où si on doit isoler un serveur chez un hébergeur X pour relancer tout un système propre chez un hébergeur Y. Il faut qu'on ait les développeurs pour pouvoir redéployer, il faut qu'on ait la personne qui gère un autre domaine dans la société qui n'est pas forcément qui puisse être en mesure de faire le changement de DNS ou en tout cas de faire nécessaire pour aiguiller le site d'une autre manière. Il faut prévenir aussi le marketing dans le sens aussi des budgets en cours sur la partie communication de les couper le temps de mitiger le trafic.
Quand on a des grosses campagnes de communication en cours régulière de résolution de l'incident. Et voilà c'est un peu ce que je veux dire par là, c'est qu'il y a toute une chaîne de personnes à mettre dans la boucle avec des actions qui peuvent être prédéfinies et c'est ce qui va permettre de rassurer la direction dans le cas d'un incident. Dans l'incident on a prévu plusieurs options et le tout c'est de les activer au moins membre tout en ayant identifié là où les personnes les plus efficaces en fonction de l'incident à venir.
-
Ça dépend toujours du business, ça dépend toujours de la société cible et de ses besoins. kslamani sociétés qui a 40 qui a plein de sites vitrines d'accord on va dire ils ont une centaine de marques avec des sites vitrines et chaque site présente sa marque et le besoin, voilà c'est un besoin fort en image de marque donc d'avoir des sites qui fonctionnent, ne pas pirater et qui peuvent générer du lead. Donc la plupart de ces sites ont un formulaire de contact qui permet de remonter des informations de contact pour une personne qui veut être contactée sous forme de mail ou autre. Et donc dans un cas comme celui-ci, le word case scénario c'est des sites qui ne fonctionnent pas ou des mails qui se perdent.
Donc toute la réflexion, toute la réflexion est de chercher à mettre en place une solution technique qui permet de mitiger ce cas-là et donc pour rentrer dans un détail un peu plus opérationnel. Le client à un moment ou un autre me dit oui on va faire simple on va mettre les sensibles sur un seul serveur ça va pas coûter cher de toute façon c'est que des WordPress c'est pas très grave et là voilà dans la logique et surtout par rapport aux besoins qui aient exprimé on a beaucoup réfléchi, on a beaucoup discuté
La menace, elle est trop forte pour mettre tous les sites sur le même serveur, donc on explique ça. Et à la fin, on décide de se dire, on va faire quelque chose de grand, mais qui va permettre à tout le monde d'être très serein. C'est qu'on va monter un mini-server par site.
Donc il y aura un serveur dédié par site vitrine, ça va permettre d'avoir une isolation et un cloisonnement complet de tous les sites, donc si 1 site qui se fait compromettre, les 99 autres n'ont aucun rapport avec le site concerné. S'il doit y avoir une compromission du système, chaque entité, chaque BU va être responsable de la restauration de son système, la restauration de ses sauvegardes et même du choix de ses prestataires parce que sur les 100 sites c'est pas le même prestataire technique, c'est pas les mêmes développeurs, c'est pas les mêmes équipes de com qui travaillent dessus.
Un autre exemple qui me vient à l'esprit. C'est le besoin en disponibilité quand il y a des équipes qui travaillent sur une plateforme en interne, donc on peut avoir des salariés, ça arrive, et donc typiquement la plateforme sur laquelle tous les salariés travaillent est indisponible. On peut pas mettre ces personnes au chômage technique donc le besoin il est assez simple, c'est pas forcément quelque chose de très complexe d'un point de vue technique, c'est pas forcément quelque chose de très complexe d'un point de vue infrastructure c'est le bon outil interne donc on va avoir au maximum 5 ou 10 accès concurrents à l'instant T donc rien d'insurmontable techniquement par contre on ne peut pas se permettre d'avoir une plateforme qui soit offline pendant une plus de 4 heures parce qu'on mettrait une quinzaine de collaborateurs aux chômages techniques, en tout cas à la machine à café et ça c'est pas forcément quelque chose d'entendable pour certains donc le besoin pour un cas comme celui-ci de voir ce qu'il y a de scénario c'est le système d'information interne ne fonctionne pas et j'ai 15 collaborateurs qui ne peuvent pas travailler correctement donc voilà la réflexion nous a amené à penser plein de choses il en est sorti une solution technique assez simple, c'est tout simplement d'avoir des sauvegardes du système d'information dans un format qui soit très rapide à redéployer.
Sans rentrer dans la partie très technique, on peut faire des sauvegardes au format zip, au format SQL, on peut faire plein de choses, mais on peut aussi faire des sauvegardes au format système pour les machines virtuelles et c'est un peu ce qui a été choisi dans cet exemple-là.
On duplique tout simplement une sauvegarde de la machine virtuelle entière sur un autre système et tout ça pour dire que si un jour il y a un problème sur le serveur qui supporte l'infra à un instant T, il suffit basiquement de rallumer la sauvegarde de l'autre côté sur un serveur qui est déjà provisionné qui contient déjà les données de la veille ou les données en tout cas les dernières qui ont été fraîchement injectées sur cette seconde plateforme et dans ces cas-là on a très rapidement un retour à la normale sur le système d'information on n'a pas été très loin dans la réflexion parce que c'était pas nécessaire on n'avait pas besoin de faire de la réplication en temps réel on aurait pu mais les budgets n'étaient pas disponibles et le besoin n'existait pas forcément pour autant que d'avoir de la réplication de données en temps réel dans l'heure sur la base de données fraîche, ayant moins de 24h.
L’idéal est de construire une analyse de risque pour se donner une grille de lecture des différents scénarios possibles, de leurs criticités, mais aussi de leur risque de survenue pour pouvoir trancher sur l’acceptation/refus des risques.

EN : Gravity : Degree of severity
EN : Probabilité : Probability to occur
Cette approche peut permettre une introspection pertinente pour une telle réflexion. Une méthodologie est ajoutée en annexe pour permettre de s’approprier la logique de raisonnement. Elle est issue du monde de la sécurité des systèmes d’information. Mais peut totalement être adaptée à un raisonnement basé sur l’infrastructure ou les besoins plus organisationnels. Des métriques métiers, spécifiques à l’entité, doivent y être intégrées pour la rendre la plus proche de la réalité possible.
Cette grille de lecture théorique est à mettre en face d’un budget pour décision.
Il est évidemment facile de refuser tous les risques lorsqu’on raisonne à budget illimité. La réalité est autre.
La notion de temps (au sens temps de retour à la normale) est également importante et c’est ce qui fait la différence entre un PRA et un PCA.
Le PRA va nécessiter la mise en place d’une chaine décisionnelle (des changes, décisions ou interventions humaines) quand le PCA peut aller jusqu’à une résilience quasi-totale, car techniquement automatisée.
Le site e-commerce < 1M CA/an
Un site e-commerce qui ne fonctionne plus est une societé qui ne fait plus de chiffre d'affaires. L’objectif est d’avoir donc le retour à la normale le plus rapide possible ; sans pour autant aller à l’encontre d’une intégrité forte. Le risque est en général accepté de restaurer une sauvegarde avec un historique inférieur à 24 h même s’il faudra réimporter dans un second temps les paniers, comptes ou commandes clients.
Aller sur un PCA avec la mise en place d’une infra complète en HA et donc des coûts d’infrastructure doublés avec réplication en temps réél des données est une option, mais qui, financièrement, peut ne pas être cohérente (tout dépend des métiers/secteurs et des sensibilités de chacun). Mais pour cet exemple, aller sur une infra à 10 K € /mois pour un cas qui arrive au max 1 fois par an, n’est pas cohérent.
Le cas type est donc la mise en place d’un PRA sous la forme : serveur principal + serveur de secours ; pré-provisionné, sur laquelle on pourrait (où on aurait déjà) importer la dernière sauvegarde générée.
La chaine de décision s’apparente à l’évaluation du temps d’interruption de service en qualifiant la panne par rapport à son temps de retour à la normale.
On se retrouve dans une situation où le site e-commerce peut être à nouveau en ligne en quelques heures/minutes.
Cas standard : sites vitrines grand groupe multimarques
Autre situation que l’on retrouve régulièrement, les sites « simples » de marque. Pas ou peu d’interaction utilisateurs, destiné à du lead par mail ou a de la mise en avant d’image de marque.
Coté technique : Le profil WordPress « simple » par excellence. Dans ce cas le besoin en disponibilité du site est très important, le code n’évolue que très rarement, la base de donnée non plus car les transactions utilisateurs sont général doublées d’un mail.
Que faire en cas de compromission d’un site ? Quelle organisation générale ? Qui ? Comment ?
La réponse en termes de besoin de l’IT groupe a été la suivante :
Il faut aller sur une approche de gouvernance numérique niveau groupe. Chaque entité « marque » doit être en mesure d’intervenir sur ses sites de manière autonomes. Chaque entité doit être financièrement responsable de ses serveurs.
Aucune perte de lead (prospect).
Hors lead (prospect), la tolérance à la « perte de donnée » est acceptée.
Déliverabilité mail forte.
Il ne doit pas y avoir de « décloisonnement » possible (image de marque importante).
La notion de webperformance est importante.
Sur cette base, il a été décidé la mise en place de N petits serveurs virtuels (cloisonnement total) avec des configurations homogènes et standardisées. L’ensemble des mails transactionnels doivent transiter via du canon à mail sur des comptes « nominatifs » (un site piraté ne peut pas impacter la déliverabilité des mails sortant des autres sites marques).
Coté sauvegardes, une rétention 15 jours distantes, mais surtout une stratégie basée sur de la restauration de snapshot système.
Chaque entité a la possibilité de restaurer son serveur via le BO de l’hébergeur sans solliciter les services IT. Et si cela n’est pas suffisant, réinitialisation complète du système et demande de redéploiement du backup « T 0 » (ou sollicitation de l’agence Web).
Vous avez aimé ce 1er chapitre ?
Envoyez-nous vos suggestions d’amélioration !
Partagez le code pour le le 1er mois offert valable jusqu’au 25 février 2024 !
6TGTBUX
Partagez votre engouement sur les réseaux sociaux en citant nos invités !
Site Web : Hypertexte.Online
X (Twitter) : Hypertextemag
Instagram : Hypertextemag
Crédits et Remerciements Chapitre #01 - 2024
Invités : Amélie Lachat, Sylvain Peyronnet, Karim Slamani
Conception et édition : Syphaïwong Bay, Lola Depret, Hélène Ioannidis, Jennifer Trouille
Sponsor : Inéolab
Partenaires : Visibrain, Neurodivergents in SEO Community
Graphisme de la Revue et de ce chapitre : Camille Remy, Syphaïwong Bay
Early-Backers : Thibault Mauger, Andrea Goulet, Pierre Calvet, Olivier Perbet, David Vandewiele, Stéphanie Prat, Rémi Nestasio, Yves Stadler, Bénédicte Didier, Anaig Nouvel, Cédric Gandolf, Cazpeyr, Régis Stéphant, Olivier de Segonzac, Areej AbuAli, Laure Peka, Farfadet, Julien Ringard, Omnireso, Amélie Mairesse, Manon Marcozzi, Eva Belgherbi, Hardisk, Maël Montarou, Marie Baillais, Magali Pha, Julien Dehee, Sarah Bob, Marie Signoret, Maxime Legendre, Cherubin13, Nicolas Piquero, Romain Guillemot, ArthurCa, Valentine Loukacheff, Camille Remy, Laura Blanchard, Coline Jacquelin, Alexandra Van Ty, Olivier Andrieu, Romain Lenglet, Thibaut Prat, Anthony Herrero, Sébastien Bulté, Sylvain Peyronnet, David Looses, Benoît Chevillot, et 10 contributeurs anonymes.